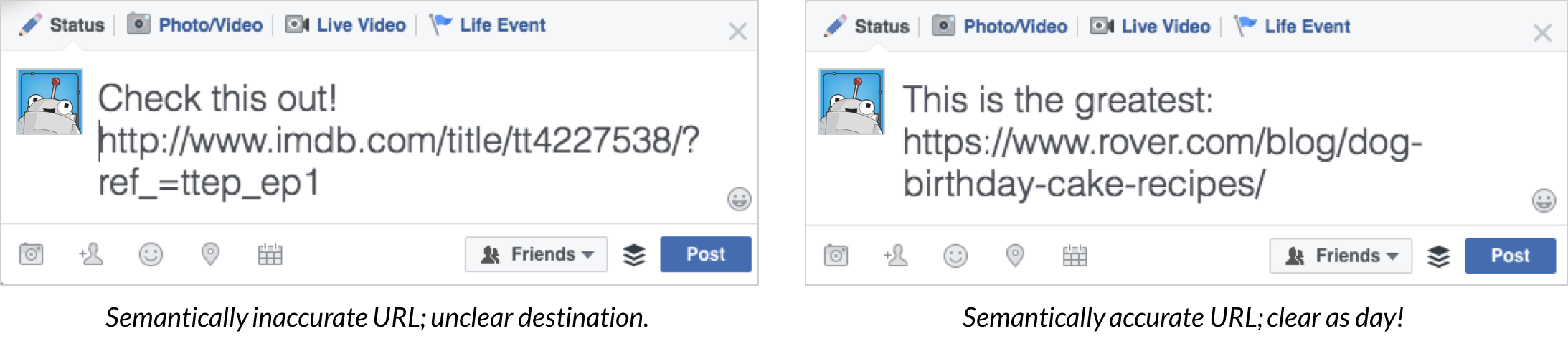
Robots.txt 文件规定了搜索引擎爬虫可以访问网站上的哪些 URLS,该文件主要用于避免网站收到过多请求,也可以通过配置该文件禁止百度等搜索引擎抓取某些 URLS。

什么是 Robots.txt 文件?
Robots.txt 是网站管理员在网站根目录创建的一个 txt 文本文件,用于规定搜索引擎爬虫如何抓取本网站页面。
如果想要通过 robots.txt 文件禁止搜索引擎抓取部分网址,以防止搜索引擎将私人照片、过期的特价商品或尚未准备好给用户访问的页面编入索引。正确使用 Robots.txt 文件有助于提升 SEO 工作的效果。
当搜索引擎爬虫机器人开始抓取内容时,会先检查是否存在阻止它们查看某些页面的 robots.txt 文件。
更多内容,可以参考下面的扩展阅读文章:
什么时候使用 Robots.txt 文件?
如果不希望搜索引擎把某些页面或内容编入索引,则可以通过 Robots.txt 文件来实现。如果允许搜索引擎(如百度、Google、Bing 和 Yahoo)访问并索引您的整个网站,则不需要 robots.txt 文件。
需要注意的是,如果其他网站有指向您网站上被阻止的页面的链接,搜索引擎可能仍会将这些 URL 编入索引。为了防止这种情况发生,可以使用 x-robots-tag、 noindex 元标签或 rel canonical 到相应的页面。
这些文件起到以下的作用:
- 将网站的某些部分保持私密。
- 防止重复内容出现在搜索结果中。
- 避免索引问题。
- 禁止 URL。
- 防止搜索引擎索引特定文件,如图像或 PDF。
- 管理抓取流量并防止媒体文件出现在搜索结果中。
- 需要对机器人进行限制的付费广告或链接。
Google 在相关文档中指出不应使用 robots.txt 从搜索结果中禁止收录某些网页。原因是,如果其他页面使用描述性文本链接到这些网页,这些页面仍然可能被编入索引。而 Noindex 指令和受密码保护的页面也许是一个更好的选择。
设置 Robots.Txt 文件
通过 Robots.txt 文件,我们可以一次允许或禁止多个页面,而无需手动配置每个页面。
robots.txt 文件规定的内容:
- 完全允许 - 可以抓取所有内容
- 完全禁止 – 无法抓取任何内容。这意味着完全阻止了搜索引擎的抓取工具访问您网站的任何部分。
- 有条件的允许 – 文件中列出的规则确定哪些内容可以抓取,哪些内容不允许抓取。
创建 Robots.txt 文件非常简单,主要涉及两个元素:“user-agent”,即其下面的 URL 块适用的搜索引擎机器人。另一个是“disallow”,即你想要禁止搜索引擎抓取的 URL。
如何配置 Robots.txt 阻止抓取 URL
对于 User-agent 行,您可以列出特定的机器人(例如 Googlebot),也可以使用星号代表适用于所有搜索引擎机器人。例如下面所示。
User-agent: *条目中的第二行 disallow 列出了您要阻止搜索引擎抓取的特定页面。要阻止抓取任何页面,可以使用正斜杠。也可以对特定的页面、目录、图像或文件类型进行限定。
Disallow: / 阻止整个站点。Disallow:/bad-directory/ 阻止目录及其所有内容。Disallow:/secret.html 阻止页面。Robots.txt 文件配置的注意事项:
- 文件必须命名为 robots.txt。
- 网站只能有 1 个 robots.txt 文件。
- robots.txt 文件必须位于其要应用到的网站主机的根目录下。例如,若要控制对
https://www.example.com/下所有网址的抓取,就必须将 robots.txt 文件放在https://www.example.com/robots.txt下,一定不能将其放在子目录中(例如https://example.com/pages/robots.txt下)。如果您不确定如何访问自己的网站根目录,或者需要相应权限才能访问,请与网站托管服务提供商联系。如果您无法访问网站根目录,请改用其他屏蔽方法(例如元标记)。 - robots.txt 文件可应用到子网域(例如
https://website.example.com/robots.txt)或非标准端口(例如http://example.com:8181/robots.txt)。 - robots.txt 文件必须是采用 UTF-8 编码(包括 ASCII)的文本文件。Google 可能会忽略不属于 UTF-8 范围的字符,从而可能会导致 robots.txt 规则无效。
Robots.txt 文件示例
下面是一个包含两条规则的简单 robots.txt 文件:
User-agent: Googlebot
Disallow: /nogooglebot/
User-agent: *
Allow: /
Sitemap: http://www.example.com/sitemap.xml以下是该 robots.txt 文件的含义:
- 名为 Googlebot 的用户代理不能抓取任何以
http://example.com/nogooglebot/开头的网址。 - 其他所有用户代理均可抓取整个网站。不指定这条规则也无妨,结果是一样的;默认行为是用户代理可以抓取整个网站。
- 该网站的站点地图文件路径为
http://www.example.com/sitemap.xml。
作者:牛奇网,本站文章均为辛苦原创,在此严正声明,本站内容严禁采集转载,面斥不雅请好自为之,本文网址:https://www.niuqi360.com/seo/how-to-prevent-search-engines-t-indexing-certain-web-pages/